Tagline
NLP pipeline mining Reddit's car subs for sentiment and topic shifts.
Tech Stack
Python , Pandas , NLTK , Gensim , Scikit-learn , PRAW , Django , Next.js
Year
2026
NLP pipeline mining Reddit's car subs for sentiment and topic shifts.
Python , Pandas , NLTK , Gensim , Scikit-learn , PRAW , Django , Next.js
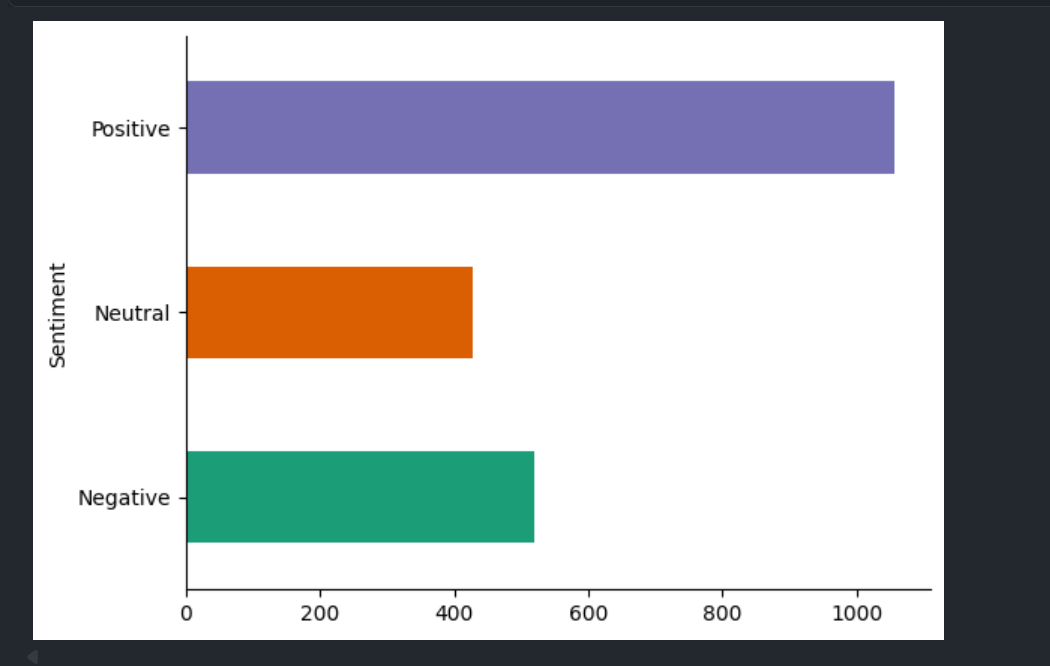
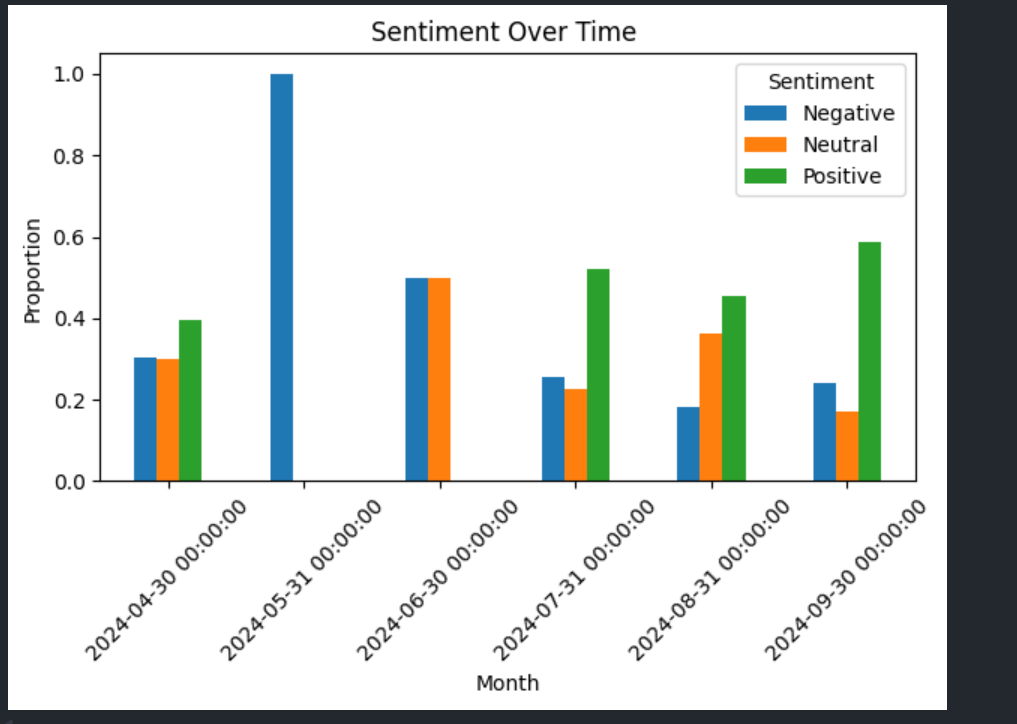
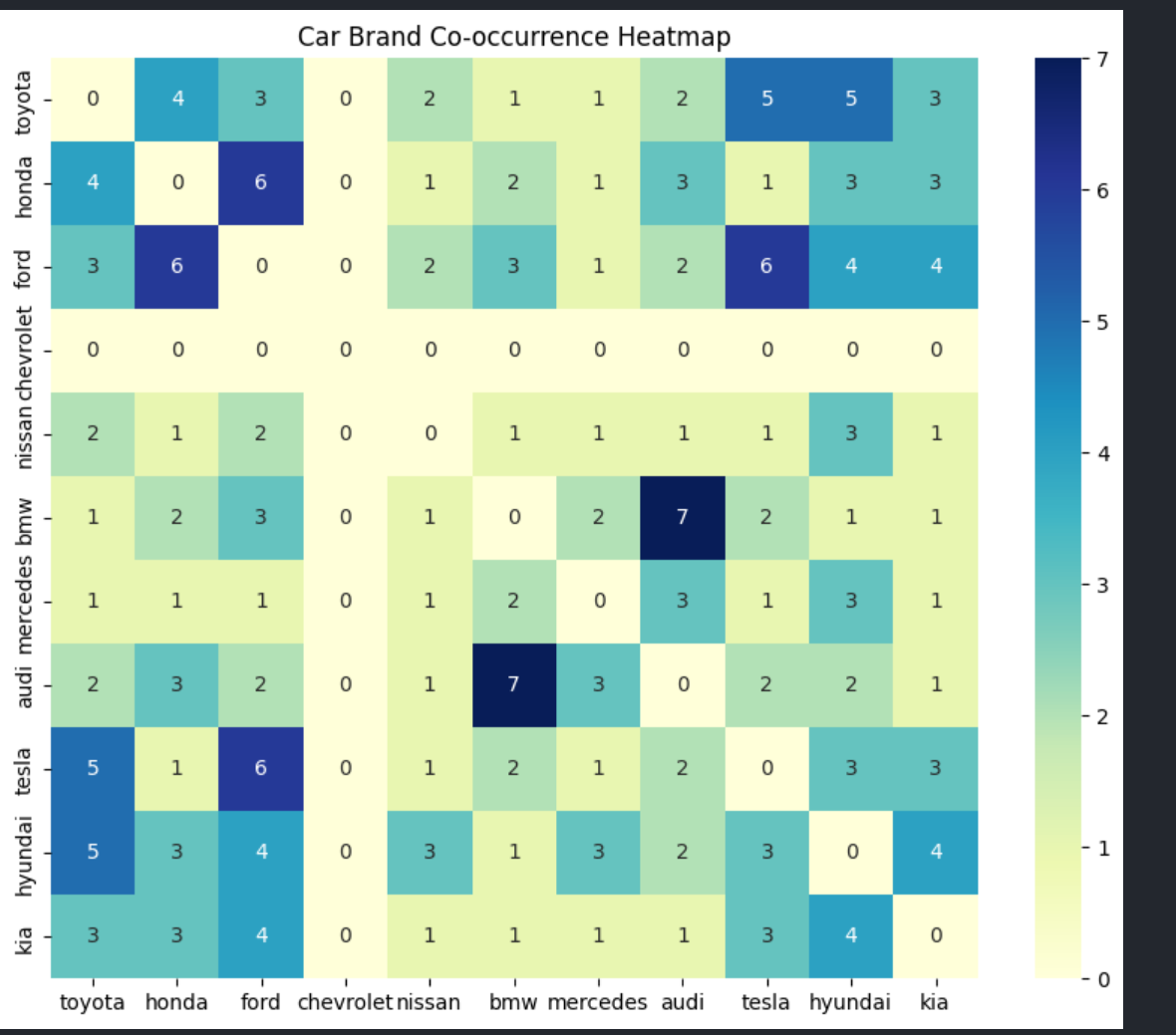
TorqueLens pulls 2,000 plus comments from five automotive subreddits and runs them through a proper NLP stack: tokenisation, stopwords, WordNet lemmas. VADER handles sentiment scoring, and two topic models (LDA on bag-of-words, NMF on TF-IDF) cross-check each other so the themes actually hold up. Output lands as wordclouds, sentiment bands over time, and an eleven-brand co-occurrence matrix. A Django API and Next.js client scaffold the dashboard around it.
PRAW scrapes 2,000+ comments across /r/cars, /r/electricvehicles, /r/whatcarshouldIbuy and two more car-focused subreddits. Raw text is persisted for reproducible runs.
PRAW · Reddit API
tap a step to explore →
TorqueLens collects 2,000+ comments across /r/cars, /r/electricvehicles, /r/whatcarshouldIbuy and related subreddits via PRAW, then runs a full NLP stack — URL stripping, NLTK tokenisation, stopword filtering, and WordNet lemmatisation. VADER compound scores classify each comment as positive, neutral, or negative; dual topic modeling (LDA on a bag-of-words corpus and NMF on a TF-IDF matrix) cross-validates the latent themes. Feature extraction adds fuel-type classification (gas / diesel / electric / hybrid) and an 11-brand co-occurrence matrix, surfacing which marques drivers discuss together.